Introduction
Let’s face it, AI is taking over. Large Language Models (LLMs), those smart AI models trained on mountains of data are now doing everything from customer service to content creation. LLMs are changing the game across a multitude of industries, but there’s a catch: the same thing that makes them so useful also makes them a prime candidate for malicious actors.
If you think about it – if an AI can write a story, it can probably write a phishing email that’s way too convincing.
In this article, we’re diving into some of the more common vulnerabilities found in LLMs and introduce you to penetration testing – the proactive way to find and fix weaknesses before the bad guys do.
The Basics
LLMs are the AI brains behind much of the technology we interact with daily. They have been fed massive amounts of data and learned to predict what comes next, making them incredibly good at generating human-like text allowing them to excel at a variety of tasks from translating languages, summarizing information, and even writing code.
Across industries, LLMs are making a wave, changing the way they operate.
Customer Service: chatbots powered by LLMs can handle customer queries 24/7, freeing up human agents for the more complex tasks.
Healthcare: LLMs can help doctors to diagnose diseases and analyze medical images, leading to faster and more accurate treatment.
Finance: Financial institutions are using LLMs to detect fraud, assess risk, summarize and process documents, and provide personalized investment advice.
The applications are endless, but in the next section we will discuss some of the vulnerabilities in LLMs that you need to be aware of.
Common Vulnerabilities
Large Language Models (LLMs) have awesome potential for boosting productivity across a range of sectors but let’s not forget that despite that awesome potential they also bring their own unique set of security challenges. Thankfully, OWASP (Open Web Application Security Project); the non-profit dedicated to improving software security, has curated another one of their well-known OWASP Top 10 initiatives specifically tailored towards LLMs:
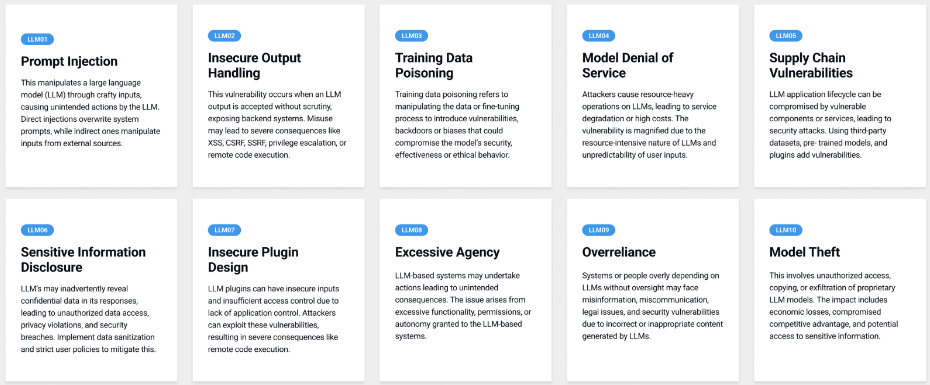
Source OWASP
Let’s have a quick look at just a few of OWASP’s Top 10 and how this could affect you.
Prompt Injection
Think of Prompt Injection as the equivalent of the Jedi mind trick. Maliciously crafted prompts can coax an LLM into performing actions or divulging information it wasn’t designed to do, potentially leaking sensitive information or even executing malicious code. This can be done directly by manipulating prompts to get a desired output or indirectly through embedding malicious prompts within a resource to be digested like a document or an image.
Malicious actors can leverage Prompt Injection to extract sensitive information from models or change the way they behave, potentially putting you at risk. Whilst Prompt Injection mainly focuses on the LLM system itself, it can indirectly affect others by violating their privacy, exposing them to harmful or inappropriate content and misinformation. For a more detailed read on Prompt Injection, Lakera has a great article which delves deeper into attack techniques and best practices for risk mitigation.
Insecure Output Handling
As LLMs become increasingly popular, more and more companies integrate these models into their applications to boost the productivity of their workers. One such example is an LLMs ability to summarize and extract information from vast spreadsheets and documents allowing users to digest information more efficiently by either displaying it within an application or exporting it into a file available for people to download.
There’s no denying it has great potential, but the flaw can lie within the implementation. Malicious actors can leverage models to bypass filters in place for the average user and conduct Cross-site Scripting attacks within applications. Consider this, a model incorporates user-input into its response which contains JavaScript code, if the response is not sanitised or validated the same way as user-input is, the code may be executed putting user accounts and personal information at risk.
Excessive Agency
Think of an LLM as your own personal agent. It has some “agency” – the ability to take actions on your behalf like sending emails and summarizing information when asked to. But what if that agent gets too independent, making decisions or performing actions beyond its intended role? Thats the problem of Excessive Agency.
Excessive Agency can allow potentially damaging actions to be performed in response to unexpected outputs from the model, whether that’s the result of malfunction, hallucinations or prompt injection). Despite there being multiple potential reasons for the unexpected output, the root cause lies with the excessive permissions and autonomy granted to it.
Consider a LLM that has granted access to your email account for the sole purpose of summarizing emails for you. If the model has been granted excessive permissions, a malfunction or unexpected output might cause it to behave in an unintended way resulting in it sending emails or blocking contacts impacting your communications.
Over-reliance
LLMs can generate some seriously convincing text, but that doesn’t mean you should blindly trust every word. It’s like having a super-smart parrot – it can mimic human speech amazingly, but it doesn’t mean it truly understands what it’s saying. Sometimes they can hallucinate and make up facts that sound legitimate, they might miss nuances of language leading to awkward misunderstandings, they may even write and suggest vulnerable code in response to a coding problem.
LLMs are really popular for assistive coding helping developers to write code more efficiently giving them more time to focus on complex tasks. Despite this, they can introduce vulnerabilities into environments if relied upon without supervision.
Canada’s largest airline was ordered to pay compensation to a customer after their chatbot gave inaccurate information leading to a purchase. The airline tried to avoid blame by claiming the chatbot was responsible for its own actions.
In the end, they are great tools but they’re not a complete substitute for your own critical thinking and judgement. Always double-check the information provided and remain vigilant. For a full breakdown of OWASPs Top 10 for LLM, see here. To help identify weaknesses within your LLM implementation, it’s recommended to conduct a penetration test.
The Role of Penetration Testing in LLM Security
A penetration test allows security professionals to conduct a controlled simulation of real-world attacks. It’s a proactive approach to finding weaknesses and vulnerabilities within an environment and implementation before attackers do. LLMs are complex systems that operate differently than everyday applications, API and infrastructure. As a result, they require a different testing approach to consider unique flaws such as prompt injection.
The value of penetration testing extends beyond identification of vulnerabilities, it offers actionable recommendations for remediations empowering you to strengthen weaknesses within your implementation. By embracing ongoing regular penetration testing as part of your LLM development and deployment strategy you proactively safeguard your AI systems and ensure they remain robust against emerging threats. As they continue to evolve and integrate deeper into our lives, prioritizing security through measures like penetration testing is not just a best practice, but a necessity.